
A back-end WebSocket for live streaming data can typically offer subscriptions to data. Your client UI will typically have one connection to your back-end for all your subscriptions. The challenge becomes how to you handle many components in your UI subscribing to it considering that
- which components are available can be user driven
- the components are not aware of each other
- each component can vary what it subscribes to based on user interactions
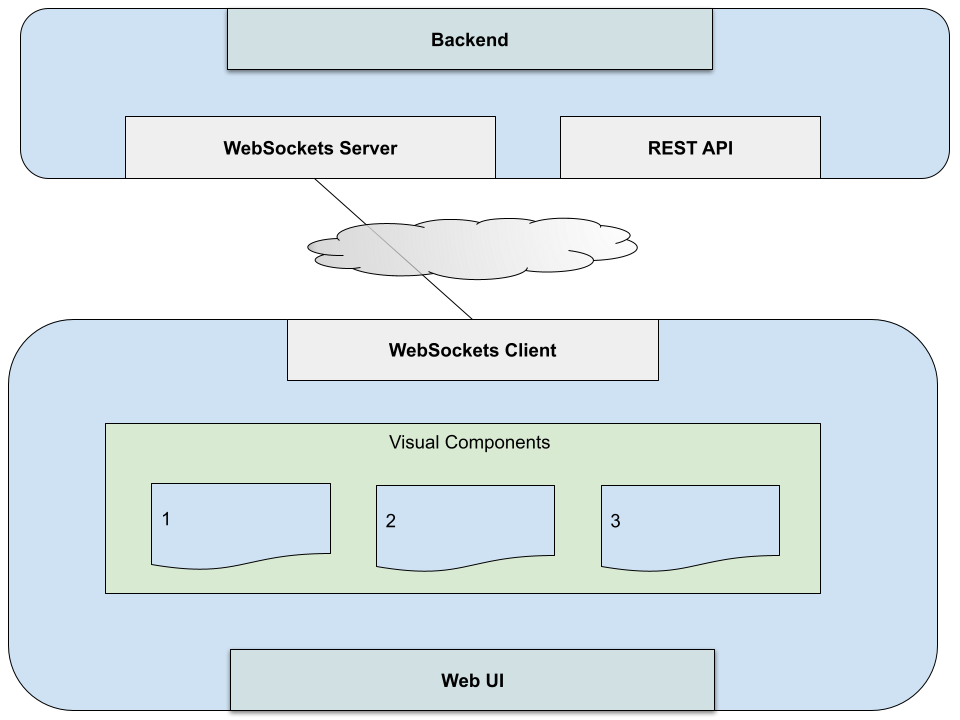
The solution to this is to centralize a pub/sub pattern near the client WebSocket connection.
Component Subscription Requirements
There are two types of subscriptions at play. One is subscribing to a topic or channel. The other is subscribing to content or data within that topic or channel.
To give an example, a market data API might provide both Level I and Level II quotes, which have very different data structures. This would be a topic or channel a component might subscribe to. Once it is listening on this channel, it may then subscribe to specific content such as quotes for IBM, TSLA and AMZN.
A component that requires Level I quotes will do two things to begin to receive data
- Listen to or observe the Level I channel
- Request a list of symbols (content) for its Level I subscription as they change
It can begin observing the channel upon creation of the component. As a user interacts and adds or removes stock symbols, it will update its list of symbols it is subscribing to.
The component sends its complete current list, not the changes. If it is subscribing to IBM, and the user adds TSLA, it will now send the new updated list of [“IBM”, “TSLA”]. If it sends an empty list, it is basically unsubscribing from the data. However, it can continue to observe the channel until it is destroyed.
As cleanup, when a component is destroyed, it should unsubscribe from the content (stock symbols) as well end its channel observation.
Subscription and Publishing Services
To handle these component data subscription requirements, we’ll add two services to our UI client.
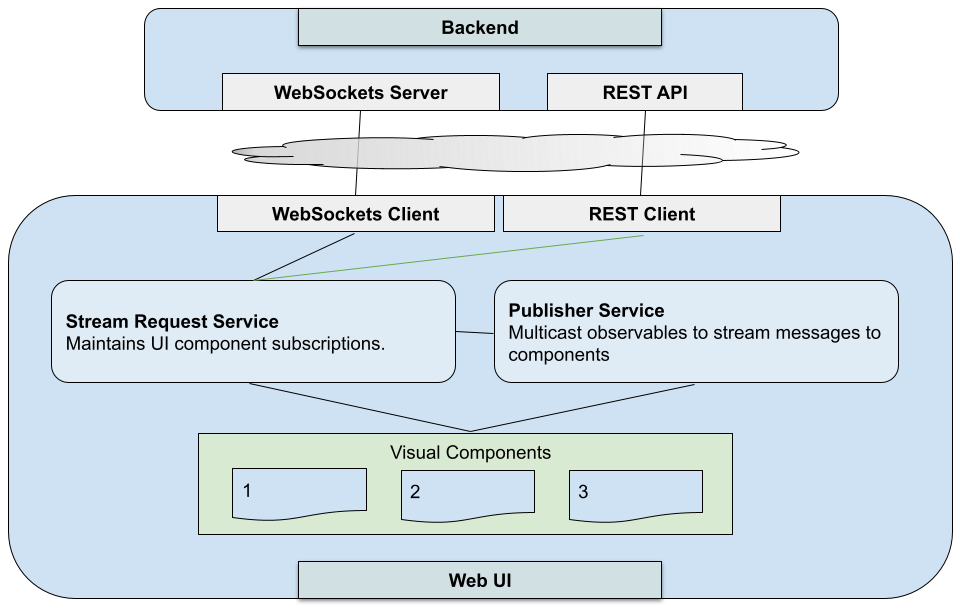
A service in the UI is an injectable singleton that handles shared state around a concern. In our case, we have one focused on content subscriptions (e.g., “IBM”), and another on channel subscriptions (e.g., “Level I”) through which the content will be broadcast.
Note that the publishing of data in your Publish Service via a pub/sub topology can happen via various techniques. In our discussion we’ll focus on using multicast (or “hot”) observables such as what is provided in the RxJS library, which has its own topic subscription semantics.
The publishing service is where you’ll have each type of channel you want. In our stock quotes example, you can have one channel for Level I quotes, and another for Level II quotes.
Both of these services are injected in each subscribing UI component and then used by the component to drive the content it receives.
As your Stream Request Service is handling the mediating to the WebSocket, it is the only service connecting to it. It is not a hard rule that this service also handle routing. It is just one way to route it. The important thing is you do have a service centrally routing your messages and connecting them to your publisher, broadcasting them to your topics based on type of content. You have a lot of freedom here on how you route messages. That really is another discussion. The important thing is that by connecting the publishers to your WebSockets through an intermediary, you have created routing ability within your UI.
The cohesion between content subscriptions and routing of incoming messages makes sense as these concepts are already tied to your WebSocket. If you have more than one back-end you are connecting to, you can create individual services for each one doing this, then optionally put them behind a facade of a single service.
Your publisher, however, should not be coupled directly with the WebSocket because it can potentially have multiple sources of data. This part of our design pattern creates loose coupling between data sources and consumers.
One thing you can do is also add a channel to your publisher just for your UI that your components can publish on, instead of just listening on. This provides a way for your components to talk back to any service without having a direct connection to it…. aka “loose coupling”. Because components can also listen to these types of channels, this becomes a means for components to talk to each other without being aware of each other’s existence. This is one of my favorite benefits of observable patterns.
Similarly, you can have a channel that talks back to your back-end service. We are already doing that in a sense by subscribing. But, you can go beyond that by, for instance, being the source of data, such as real-time sensors or crowd sourced information.
Note that while we haven’t discussed it, we have the option of a REST service in this topology. This is because some back-ends will require REST calls to subscribe to data, while others will require messages via your WebSockets pipe. If you are just subscribing to data, there is no real right or wrong answer for which method is ideal. The important thing is that once the subscription is honored, receiving data comes through the WebSocket to provide one consistent pipeline of a single timeline. The client hopefully never has to combine REST and WebSockets to construct the actual state of data being subscribed to. That is, you wouldn’t want to have to combine both REST and WebSockets to construct the complete quote of IBM. Your WebSocket provides a single timeline of streaming events and data so your UI components can focus on consumption and presentation.













